Transmogrification of truth in economics textbooks — expected utility theory
from Lars Syll
Although the expected utility theory is obviously both theoretically and descriptively inadequate, colleagues and microeconomics textbook writers all over the world gladly continue to use it, as though its deficiencies were unknown or unheard of.
Not even Robert Frank — in one of my favourite intermediate textbooks on microeconomics — manages to get it quite right on this issue:
As a general rule, human nature obviously prefers certainty to risk. At the same time, however, risk is an inescapable part of the environment. People naturally want the largest possible gain and the smallest possible risk, but most of the time we are forced to trade risk and gain off against one another.
When choosing between two risky alternatives, we are forced to recognize this trade-off explicitly. In such cases, we cannot escape the cognitive effort required to reach a sensible decision. But when one of the alternatives is riskless, it is often easier simply to choose it and not waste too much effort on the decision. What this pattern of behavior fails to recognize, however, is that choosing a sure win of $30 over an 80 percent chance to win $45 does precious little to reduce any of the uncertainty that really matters in life.
On the contrary, when only small sums of money are at stake, a compelling case can be made that the only sensible strategy is to choose the alternative with the highest expected value. The argument for this strategy … rests on the law of large numbers. Here, the law tells us that if we take a large number of independent gambles and pool them, we can be very confident of getting almost exactly the sum of their expected values. As a decision maker, the trick is to remind yourself that each small risky choice is simply part of a much larger collection. After all, it takes the sting out of an occasional small loss to know that following any other strategy would have led to a virtually certain large loss.
To illustrate, consider again the choice between the sure gain of $30 and the 80 percent chance to win $45, and suppose you were confronted with the equivalent of one such choice each week. Recall that the gamble has an expected value of $36, $6 more than the sure thing. By always choosing the “risky” alternative, your expected gain — over and beyond the gain from the sure alternative — will be $312 each year. Students who have had an introductory course in probability can easily show that the probability you would have come out better by choosing the sure alternative in any year is less than 1 percent. The long-run opportunity cost of following a risk-averse strategy for decisions involving small outcomes is an almost sure LOSS of considerable magnitude. By thinking of your problem as that of choosing a policy for dealing with a large number of choices of the same type, a seemingly risky strategy is transformed into an obviously very safe one.

What Frank — and other textbook authors — tries to do in face of the obvious behavioural inadequacies of the expected utility theory, is to marginally mend it. But that cannot be the right attitude when facing scientific anomalies. When models are plainly wrong, you’d better replace them! As Matthew Rabin and Richard Thaler have it in Risk Aversion:
It is time for economists to recognize that expected utility is an ex-hypothesis, so that we can concentrate our energies on the important task of developing better descriptive models of choice under uncertainty.
If a friend of yours offered you a gamble on the toss of a coin where you could lose €100 or win €200, would you accept it? Probably not. But if you were offered to make one hundred such bets, you would probably be willing to accept it, since most of us see that the aggregated gamble of one hundred 50–50 lose €100/gain €200 bets has an expected return of €5000 (and making our probabilistic calculations we find out that there is only a 0.04% risk of losing any money).
Unfortunately – at least if you want to adhere to the standard neoclassical expected utility maximization theory – you are then considered irrational! A neoclassical utility maximizer that rejects the single gamble should also reject the aggregate offer.
In his modern classic Risk Aversion and Expected-Utility Theory: A Calibration Theorem Matthew Rabin writes:
Using expected-utility theory, economists model risk aversion as arising solely because the utility function over wealth is concave. This diminishing-marginal-utility-of-wealth theory of risk aversion is psychologically intuitive, and surely helps explain some of our aversion to large-scale risk: We dislike vast uncertainty in lifetime wealth because a dollar that helps us avoid poverty is more valuable than a dollar that helps us become very rich.
Yet this theory also implies that people are approximately risk neutral when stakes are small. Arrow (1971, p. 100) shows that an expected-utility maximizer with a differentiable utility function will always want to take a sufficiently small stake in any positive-expected-value bet. That is, expected-utility maximizers are (almost everywhere) arbitrarily close to risk neutral when stakes are arbitrarily small. While most economists understand this formal limit result, fewer appreciate that the approximate risk-neutrality prediction holds not just for negligible stakes, but for quite sizable and economically important stakes. Economists often invoke expected-utility theory to explain substantial (observed or posited) risk aversion over stakes where the theory actually predicts virtual risk neutrality.While not broadly appreciated, the inability of expected-utility theory to provide a plausible account of risk aversion over modest stakes has become oral tradition among some subsets of researchers, and has been illustrated in writing in a variety of different contexts using standard utility functions.
In this paper, I reinforce this previous research by presenting a theorem which calibrates a relationship between risk attitudes over small and large stakes. The theorem shows that, within the expected-utility model, anything but virtual risk neutrality over modest stakes implies manifestly unrealistic risk aversion over large stakes. The theorem is entirely ‘‘non-parametric’’, assuming nothing about the utility function except concavity. In the next section I illustrate implications of the theorem with examples of the form ‘‘If an expected-utility maximizer always turns down modest-stakes gamble X, she will always turn down large-stakes gamble Y.’’ Suppose that, from any initial wealth level, a person turns down gambles where she loses $100 or gains $110, each with 50% probability. Then she will turn down 50-50 bets of losing $1,000 or gaining any sum of money. A person who would always turn down 50-50 lose $1,000/gain $1,050 bets would always turn down 50-50 bets of losing $20,000 or gaining any sum. These are implausible degrees of risk aversion. The theorem not only yields implications if we know somebody will turn down a bet for all initial wealth levels. Suppose we knew a risk-averse person turns down 50-50 lose $100/gain $105 bets for any lifetime wealth level less than $350,000, but knew nothing about the degree of her risk aversion for wealth levels above $350,000. Then we know that from an initial wealth level of $340,000 the person will turn down a 50-50 bet of losing $4,000 and gaining $635,670.
The intuition for such examples, and for the theorem itself, is that within the expected-utility framework turning down a modest-stakes gamble means that the marginal utility of money must diminish very quickly for small changes in wealth. For instance, if you reject a 50-50 lose $10/gain $11 gamble because of diminishing marginal utility, it must be that you value the 11th dollar above your current wealth by at most 10/11 as much as you valued the 10th-to-last-dollar of your current wealth.
Iterating this observation, if you have the same aversion to the lose $10/gain $11 bet if you were $21 wealthier, you value the 32nd dollar above your current wealth by at most 10/11 x 10/11 ~ 5/6 as much as your 10th-to-last dollar. You will value your 220th dollar by at most 3/20 as much as your last dollar, and your 880 dollar by at most 1/2000 of your last dollar. This is an absurd rate for the value of money to deteriorate — and the theorem shows the rate of deterioration implied by expected-utility theory is actually quicker than this. Indeed, the theorem is really just an algebraic articulation of how implausible it is that the consumption value of a dollar changes significantly as a function of whether your lifetime wealth is $10, $100, or even $1,000 higher or lower. From such observations we should conclude that aversion to modest-stakes risk has nothing to do with the diminishing marginal utility of wealth.
Expected-utility theory seems to be a useful and adequate model of risk aversion for many purposes, and it is especially attractive in lieu of an equally tractable alternative model. ‘‘Extremelyconcave expected utility’’ may even be useful as a parsimonious tool for modeling aversion to modest-scale risk. But this and previous papers make clear that expected-utility theory is manifestly not close to the right explanation of risk attitudes over modest stakes. Moreover, when the specific structure of expected-utility theory is used to analyze situations involving modest stakes — such as in research that assumes that large-stake and modest-stake risk attitudes derive from the same utility-for-wealth function — it can be very misleading. In the concluding section, I discuss a few examples of such research where the expected-utility hypothesis is detrimentally maintained, and speculate very briefly on what set of ingredients may be needed to provide a better account of risk attitudes. In the next section, I discuss the theorem and illustrate its implications …
Expected-utility theory makes wrong predictions about the relationship between risk aversion over modest stakes and risk aversion over large stakes. Hence, when measuring risk attitudes maintaining the expected-utility hypothesis, differences in estimates of risk attitudes may come from differences in the scale of risk comprising data sets, rather than from differences in risk attitudes of the people being studied. Data sets dominated by modest-risk investment opportunities are likely to yield much higher estimates of risk aversion than data sets dominated by larger-scale investment opportunities. So not only are standard measures of risk aversion somewhat hard to interpret given that people are not expected-utility maximizers, but even attempts to compare risk attitudes so as to compare across groups will be misleading unless economists pay due attention to the theory’s calibrational problems …
Indeed, what is empirically the most firmly established feature of risk preferences, loss aversion, is a departure from expected-utility theory that provides a direct explanation for modest-scale risk aversion. Loss aversion says that people are significantly more averse to losses relative to the status quo than they are attracted by gains, and more generally that people’s utilities are determined by changes in wealth rather than absolute levels. Preferences incorporating loss aversion can reconcile significant small-scale risk aversion with reasonable degrees of large-scale risk aversion … Variants of this or other models of risk attitudes can provide useful alternatives to expected-utility theory that can reconcile plausible risk attitudes over large stakes with non-trivial risk aversion over modest stakes.
In a similar vein, Daniel Kahneman writes — in Thinking, Fast and Slow – that expected utility theory is seriously flawed since it doesn’t take into consideration the basic fact that people’s choices are influenced by changes in their wealth. Where standard microeconomic theory assumes that preferences are stable over time, Kahneman and other behavioural economists have forcefully again and again shown that preferences aren’t fixed, but vary with different reference points. How can a theory that doesn’t allow for people having different reference points from which they consider their options have an almost axiomatic status within economic theory?
The mystery is how a conception of the utility of outcomes that is vulnerable to such obvious counterexamples survived for so long. I can explain it only by a weakness of the scholarly mind … I call it theory-induced blindness: once you have accepted a theory and used it as a tool in your thinking it is extraordinarily difficult to notice its flaws … You give the theory the benefit of the doubt, trusting the community of experts who have accepted it … But they did not pursue the idea to the point of saying, “This theory is seriously wrong because it ignores the fact that utility depends on the history of one’s wealth, not only present wealth.”
On a more economic-theoretical level, information theory – and especially the so called the Kelly theorem – also highlights the problems concerning the neoclassical theory of expected utility.  Suppose I want to play a game. Let’s say we are tossing a coin. If heads comes up, I win a dollar, and if tails comes up, I lose a dollar. Suppose further that I believe I know that the coin is asymmetrical and that the probability of getting heads (p) is greater than 50% – say 60% (0.6) – while the bookmaker assumes that the coin is totally symmetric. How much of my bankroll (T), should I optimally invest in this game?
Suppose I want to play a game. Let’s say we are tossing a coin. If heads comes up, I win a dollar, and if tails comes up, I lose a dollar. Suppose further that I believe I know that the coin is asymmetrical and that the probability of getting heads (p) is greater than 50% – say 60% (0.6) – while the bookmaker assumes that the coin is totally symmetric. How much of my bankroll (T), should I optimally invest in this game?
A strict neoclassical utility-maximizing economist would suggest that my goal should be to maximize the expected value of my bankroll (wealth), and according to this view, I ought to bet my entire bankroll.
Does that sound rational? Most people would answer no to that question. The risk of losing is so high, that I already after few games played – the expected time until my first loss arises is 1/(1-p), which in this case is equal to 2.5 – with a high likelihood would be losing and thereby become bankrupt. The expected-value maximizing economist does not seem to have a particularly attractive approach.

So what’s the alternative? One possibility is to apply the so-called Kelly-strategy – after the American physicist and information theorist John L. Kelly, who in the article A New Interpretation of Information Rate (1956) suggested this criterion for how to optimize the size of the bet – under which the optimum is to invest a specific fraction (x) of wealth (T) in each game. How do we arrive at this fraction?
When I win, I have (1 + x) times more than before, and when I lose (1 – x) times less. After nrounds, when I have won v times and lost n – v times, my new bankroll (W) is
(1) W = (1 + x)v(1 – x)n – v T
The bankroll increases multiplicatively – “compound interest” – and the long-term average growth rate for my wealth can then be easily calculated by taking the logarithms of (1), which gives
(2) log (W/ T) = v log (1 + x) + (n – v) log (1 – x).
If we divide both sides by n we get
(3) [log (W / T)] / n = [v log (1 + x) + (n – v) log (1 – x)] / n
The left hand side now represents the average growth rate (g) in each game. On the right hand side the ratio v/n is equal to the percentage of bets that I won, and when n is large, this fraction will be close to p. Similarly, (n – v)/n is close to (1 – p). When the number of bets is large, the average growth rate is
(4) g = p log (1 + x) + (1 – p) log (1 – x).
Now we can easily determine the value of x that maximizes g:
(5) d [p log (1 + x) + (1 – p) log (1 – x)]/d x = p/(1 + x) – (1 – p)/(1 – x) => p/(1 + x) – (1 – p)/(1 – x) = 0 =>
(6) x = p – (1 – p)
Since p is the probability that I will win, and (1 – p) is the probability that I will lose, the Kelly strategy says that to optimize the growth rate of your bankroll (wealth) you should invest a fraction of the bankroll equal to the difference of the likelihood that you will win or lose. In our example, this means that I have in each game to bet the fraction of x = 0.6 – (1 – 0.6) ≈ 0.2 – that is, 20% of my bankroll. The optimal average growth rate becomes
(7) 0.6 log (1.2) + 0.4 log (0.8) ≈ 0.02.
If I bet 20% of my wealth in tossing the coin, I will after 10 games on average have 1.0210 times more than when I started (≈ 1.22 times more).
This game strategy will give us an outcome in the long run that is better than if we use a strategy building on the neoclassical economic theory of choice under uncertainty (risk) – expected value maximization. If we bet all our wealth in each game we will most likely lose our fortune, but because with low probability we will have a very large fortune, the expected value is still high. For a real-life player – for whom there is very little to benefit from this type of ensemble-average – it is more relevant to look at time-average of what he may be expected to win (in our game the averages are the same only if we assume that the player has a logarithmic utility function). What good does it do me if my tossing the coin maximizes an expected value when I might have gone bankrupt after four games played? If I try to maximize the expected value, the probability of bankruptcy soon gets close to one. Better then to invest 20% of my wealth in each game and maximize my long-term average wealth growth!
When applied to the neoclassical theory of expected utility, one thinks in terms of “parallel universe” and asks what is the expected return of an investment, calculated as an average over the “parallel universe”? In our coin toss example, it is as if one supposes that various “I” are tossing a coin and that the loss of many of them will be offset by the huge profits one of these “I” does. But this ensemble-average does not work for an individual, for whom a time-average better reflects the experience made in the “non-parallel universe” in which we live.
The Kelly strategy gives a more realistic answer, where one thinks in terms of the only universe we actually live in, and ask what is the expected return of an investment, calculated as an average over time.
Since we cannot go back in time – entropy and the “arrow of time ” make this impossible – and the bankruptcy option is always at hand (extreme events and “black swans” are always possible) we have nothing to gain from thinking in terms of ensembles .
Actual events follow a fixed pattern of time, where events are often linked in a multiplicative process (as e. g. investment returns with “compound interest”) which is basically non-ergodic.
Instead of arbitrarily assuming that people have a certain type of utility function – as in the neoclassical theory – the Kelly criterion shows that we can obtain a less arbitrary and more accurate picture of real people’s decisions and actions by basically assuming that time is irreversible. When the bankroll is gone, it’s gone. The fact that in a parallel universe it could conceivably have been refilled, are of little comfort to those who live in the one and only possible world that we call the real world.
Our coin toss example can be applied to more traditional economic issues. If we think of an investor, we can basically describe his situation in terms of our coin toss. What fraction (x) of his assets (T) should an investor – who is about to make a large number of repeated investments – bet on his feeling that he can better evaluate an investment (p = 0.6) than the market (p = 0.5)? The greater the x, the greater is the leverage. But also – the greater is the risk. Since p is the probability that his investment valuation is correct and (1 – p) is the probability that the market’s valuation is correct, it means the Kelly strategy says he optimizes the rate of growth on his investments by investing a fraction of his assets that is equal to the difference in the probability that he will “win” or “lose”. In our example this means that he at each investment opportunity is to invest the fraction of x = 0.6 – (1 – 0.6), i.e. about 20% of his assets. The optimal average growth rate of investment is then about 11% (0.6 log (1.2) + 0.4 log (0.8)).
Kelly’s criterion shows that because we cannot go back in time, we should not take excessive risks. High leverage increases the risk of bankruptcy. This should also be a warning for the financial world, where the constant quest for greater and greater leverage – and risks – creates extensive and recurrent systemic crises. A more appropriate level of risk-taking is a necessary ingredient in a policy to come to curb excessive risk taking.
The works of people like Rabin, Thaler, Kelly, and Kahneman, show that expected utility theory is in deed transmogrifying truth. It’s an “ex-hypthesis” – or as Monty Python has it:
This parrot is no more! He has ceased to be! ‘E’s expired and gone to meet ‘is maker! ‘E’s a stiff! Bereft of life, ‘e rests in peace! If you hadn’t nailed ‘im to the perch ‘e’d be pushing up the daisies! ‘Is metabolic processes are now ‘istory! ‘E’s off the twig! ‘E’s kicked the bucket, ‘e’s shuffled off ‘is mortal coil, run down the curtain and joined the bleedin’ choir invisible!! THIS IS AN EX-PARROT!!
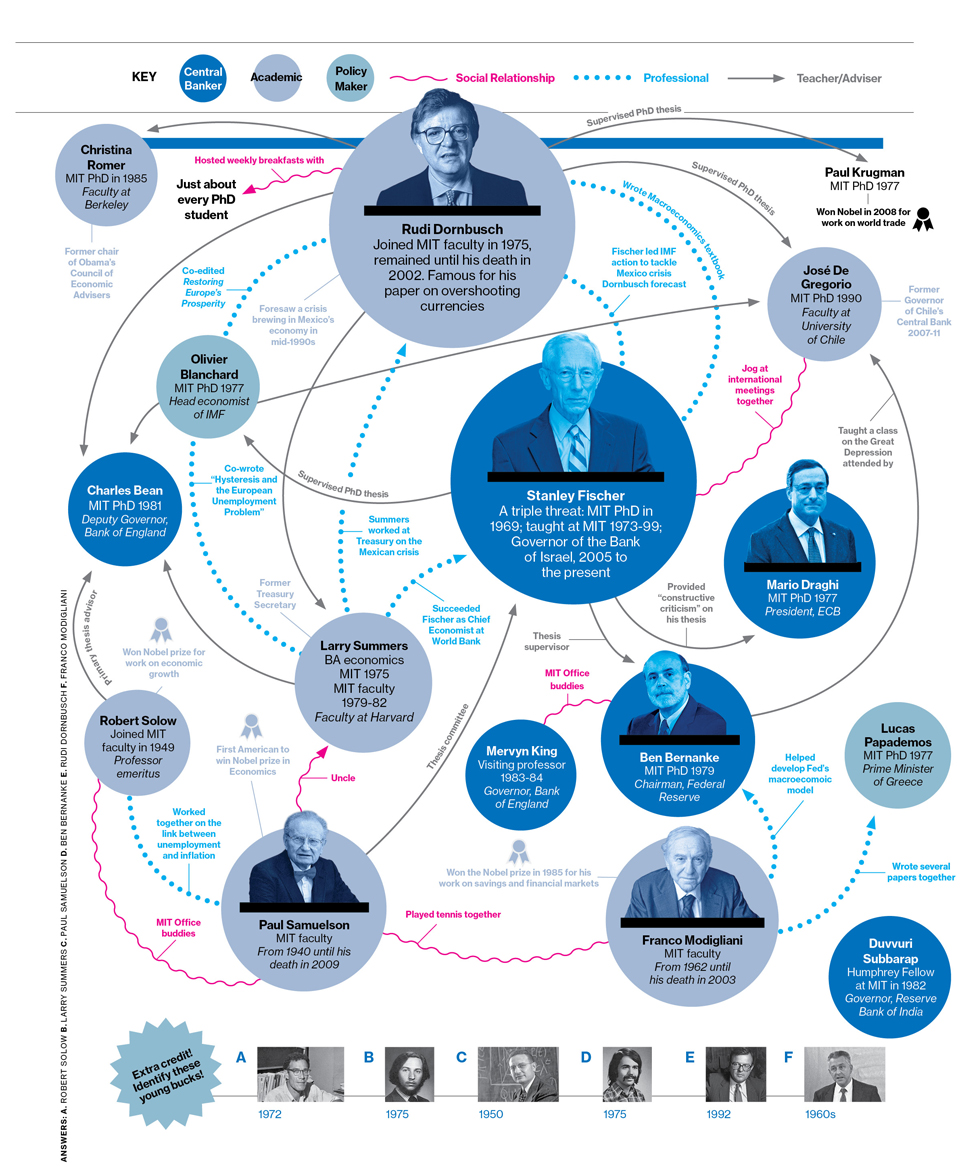
All in the family: Krugman, Summers, Fisher, . . . .
from David Ruccio
My better half has insisted for years that I not be too hard on Paul Krugman. The enemy of my enemy. Popular Front. And all that. . .
But enough is enough.
I simply can’t let Krugman [ht: br] get away with writing off a large part of contemporary economic discourse (not to mention of the history of economic thought) and with his declaration that Larry Summers has “laid down what amounts to a very radical manifesto” (not to mention the fact that I was forced to waste the better part of a quarter of an hour this morning listening to Summers’s talk in honor of Stanley Fischer at the IMF Economic Forum, during which he announces that he’s finally discovered the possibility that the current level of economic stagnation may persist for some time).
Krugman may want to curse Summers out of professional jealousy. Me, I want to curse the lot of them—not only the MIT family but mainstream economists generally—for their utter cluelessness when it comes to making sense of (and maybe, eventually, actually doing something about) the current crises of capitalism.
So, what is he up to? Basically, Krugman showers Summers in lavish praise for his belated, warmed-over, and barely intelligible argument that attains what little virtue it has about the economic challenges we face right now by vaguely resembling the most rudimentary aspects of what people who read and build on the ideas of Marx, Kalecki, Minsky, and others have been saying and writing for years. The once-and-former-failed candidate for head of the Federal Reserve begins with the usual mainstream conceit that they successfully solved the global financial crash of 2008 and that current economic events bear no resemblance to the First Great Depression. But then reality sinks in: since in their models the real interest-rate consistent with full employment is currently negative (and therefore traditional monetary policy doesn’t amount to much more than pushing on a string), we may be in for a rough ride (with high output gaps and persistent unemployment) for some unknown period of time. And, finally, an admission that the conditions for this “secular stagnation” may actually have characterized the years of bubble and bust leading up to the crisis of 2007-08.
That’s where Krugman chimes in, basking in the glow of his praise for Summers, expressing for the umpteenth time the confidence that his simple Keynesian model of the liquidity trap and zero lower bound has been vindicated. The problem is, Summers can’t even give Alvin Hansen, the first American economist to explicate and domesticate Keynes’s ideas, and the one who first came up with the idea of secular stagnation based on the Bastard Keynesian IS-LM model, his due (although Krugman does at least mention Hansen and provide a link). I guess it’s simply too much to expect they actually recognize, read, and learn from other traditions within economics, concerning such varied topics as the role of the Industrial Reserve Army in setting wages, political business cycles, financial fragility, and much more.
And things only go down from there. Because the best Summers and Krugman can do by way of attempting to explain the possibility of secular stagnation is not to analyze the problems embedded in and created by existing economic institutions but, instead, to invoke that traditional deus ex machina, demography.
Now look forward. The Census projects that the population aged 18 to 64 will grow at an annual rate of only 0.2 percent between 2015 and 2025. Unless labor force participation not only stops declining but starts rising rapidly again, this means a slower-growth economy, and thanks to the accelerator effect, lower investment demand.
You would think that a decent economist, not even a particularly left-wing one, might be able to imagine the possibility that a labor shortage might cause higher real wages, which might have myriad other effects, many of them really, really good—not only for people who continue to be forced to have the freedom to sell their ability to work but also for their families, their neighbors, and for lots of other participants in the economy. But, apparently, stagnant wages (never mind supply-and-demand) are just as “natural” as Wicksell’s natural interest rate.
And then, finally, this gem:
The point is that it’s not hard to think of reasons why the liquidity trap could be a lot more persistent than anyone currently wants to admit.
No, it’s not hard to think of many such reasons. But when the question is asked in the particular way Krugman poses it—in terms of natural rates of this and that, of interest-rates, population, wages, innovation, and so on—the only answers that need be admitted into the discussion come from other members of the close-knit family (and thus from Summers, Paul Samuelson, and Robert Gordon). All of the other interesting work that has been conducted in the history of economic thought and by contemporary economists concerning in-built crisis tendencies, long-wave failures of growth, endogenous technical innovation, financial speculation, and so on is simply excluded from the discussion.
It is no wonder, then, that mainstream economists—even the best of them—are so painfully inarticulate and hamstrung when it comes to making sense of the current economic malaise.
I’ll admit, it wouldn’t be so bad if it was just a matter of professional jealousy and their not being able to analyze what is going on except through the workings of a small number of familiar assumptions and models. They talk as if it’s only their academic reputations that are on the line. But we can’t forget there are millions and millions of people, young and old, in the United States and around the world, whose lives hang in the balance—well-intentioned and hard-working people who are being made to pay the costs of economists like Krugman attempting to keep things all in the family.
Paul Krugman and John Taylor are *both* wrong about inflation (2 graphs)
Paul Krugman does not agree with John Taylor, who suggests that we should look at the GDP deflator as well as house prices to gauge inflation. Krugman more or less proposes that we should look at core inflation instead, just like the Fed (which however uses this metric as onlyone of its sources of information). But Taylor is right that we have to look at a broader inflation metric than just consumer price inflation. We should just not look at the GDP deflator asthis is crucially, crucially influenced by the terms of trade. We have to look at domestic demand inflation, which tracks the price level of total domestic demand, i.e. not just household consumption but also investments and ‘government consumption’(street lights, education etc.) and which shows crucial differences with consumer price inflation as well as the GDP-deflator.
Krugman states about the GDP-deflator:
it contains things like grain and oil prices, which fluctuate a lot, so that it’s an unstable measure that is highly unreliable as an indicator of underlying inflation.
But the real problem with the GDP deflator is much more fundamental. It is directly influenced by changes in the terms of trade (the relation between import prices and export prices) and therewith by the exchange rate. Which means that focusing on the GDP deflator can lead to large and dangerous policy mistake of confusing an increase in the terms of trade with an increase in the domestic price level as I showed on this blog, two months ago:
After 2010-Q2 the terms of trade of the Eurozone increased which means that GDP-deflator inflation increased while all other inflation metrics decreased! So, Taylor is wrong when he focuses on GDP inflation. As I myself by the way also did for quite some time, on this blog, but the anomaly between GDP deflator inflation and other inflation metrics shown by the graph led me to re-investigate the matter
.My index of choice is domestic demand inflation (although even this metric does not encompass ‘asset price inflation’, most notably of course house price increases). One practical difference: as government wages, all over Europe, are decreasing more or increasing less than wages in the private sector this means that, at this moment, EU domestic demand inflation is lower than consumption price inflation…
The superiority of domestic demand inflation shows when we compare the difference between consumer price inflation in Spain and Germany with the difference between German and Spanish domestic demand inflation (graph).
Before as well as after 2008 domestic demand inflation differences were larger than differences in consumer price inflation, although with an opposite sign during the boom and the bust. Which of course also means that Spanish disinflation is larger than generally assumed. The differences are, in the medium run (i.e. five to eight years), about as large as differences between the GDP-deflator and consumption price inflation. In the short run (i.e. one to three years) the level of domestic demand inflation however does not show the anomalous increase of the GDP-deflator, caused by the increase of the Eurozone terms of trade (and you really do not want an inflation metric which is directly influenced by the exchange rate).
As, according to the national accounts, final demand equals income this also means that Spanish nominal incomes increased, for seven years in a stretch, 3% a year faster than German incomes, just because of these price increases and aside of increases caused by higher real production. Which goes a long way to explain the surge in Spanish imports which caused the large deficits on the Spanish current account (contrary to ECB/EC/IMF/OECD mythology, Spanish exports did well during this period!). Aside – this speech by ECB board member Jorg Asmussen made my day: by now he finally admits the relation between devastating capital flows, bubbles and accompanying increases of the price level and unsustainable current account deficits.
As a practical matter: Estonian consumer price inflation has been quite high after Estonia entered the Eurozone, which might indicate ‘Spanish’ problems. But domestic demand inflation is slightly lower than consumer price inflation which is an indication that the problem is not as severe as suggested by consumer prices (while higher inflation of course does ease the Estonian international debt burden!). But they do have a problem with house prices, again.
And, John, put in more graphs in your blogs.